3.6 KiB
Introduction
Workflow
The generation of the model is controlled by the workflow management system Snakemake. In a nutshell, the Snakefile declares for each python script in the scripts directory a rule which describes which files the scripts consume and produce (their corresponding input and output files). The snakemake tool then runs the scripts in the correct order according to the rules' input/output dependencies. Moreover, it is able to track, what parts of the workflow have to be regenerated, when a data file or a script is modified/updated.
For instance an invocation to
System Message: WARNING/2 (<stdin>, line 18)
Cannot analyze code. Pygments package not found.
.. code:: bash
.../pypsa-eur % snakemake networks/elec_s_128.nc
follows this dependency graph:
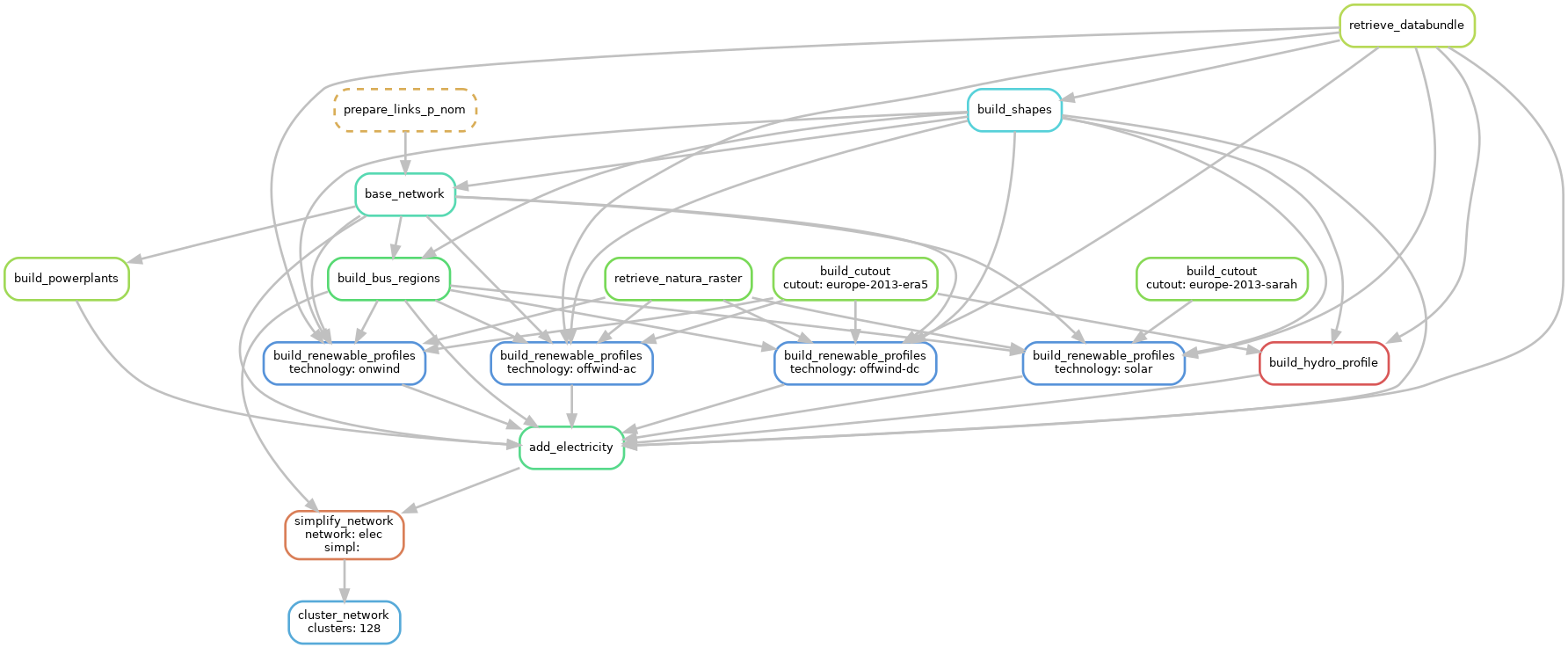
The blocks represent the individual rules which are required to create the file networks/elec_s_128.nc. The arrows indicate the outputs from preceding rules which a particular rule takes as input data.
Note
The dependency graph shown above was generated using snakemake --dag networks/elec_s_128.nc | dot -Tpng > workflow.png
For the use of snakemake, it makes sense to familiarize oneself quickly with its basic tutorial and then read carefully through the section Executing Snakemake, noting the arguments -n, -r, but also --dag, -R and -t.
Scenarios, Configuration and Modification
It is easy to run PyPSA-Eur for multiple scenarios using the wildcards feature of snakemake. Wildcards allow to generalise a rule to produce all files that follow a regular expression pattern, which e.g. defines one particular scenario. One can think of a wildcard as a parameter that shows up in the input/output file names and thereby determines which rules to run, what data to retrieve and what files to produce. Details are explained in :ref:`wildcards` and :ref:`scenario`.
System Message: ERROR/3 (<stdin>, line 37); backlink
Unknown interpreted text role "ref".System Message: ERROR/3 (<stdin>, line 37); backlink
Unknown interpreted text role "ref".The model also has several further configuration options collected in the config.yaml file located in the root directory, which that are not part of the scenarios. All options are explained in detail in :ref:`config`.
System Message: ERROR/3 (<stdin>, line 39); backlink
Unknown interpreted text role "ref".Folder Structure
- data: Includes input data that is not produced by any snakemake rule.
- scripts: Includes all the Python scripts executed by the snakemake rules.
- resources: Stores intermediate results of the workflow which can be picked up again by subsequent rules.
- networks: Stores intermediate, unsolved stages of the PyPSA network that describes the energy system model.
- results: Stores the solved PyPSA network data, summary files and plots.
- benchmarks: Stores snakemake benchmarks.
- logs: Stores log files about solving, including the solver output, console output and the output of a memory logger.