| dmc2gym | ||
| local_dm_control_suite | ||
| results | ||
| .gitignore | ||
| conda_env.yml | ||
| decoder.py | ||
| encoder.py | ||
| graphs_plot.py | ||
| LICENSE | ||
| logger.py | ||
| README.md | ||
| sac_ae.py | ||
| train.py | ||
| utils.py | ||
| video.py | ||
SAC+AE implementation in PyTorch
This is PyTorch implementation of SAC+AE from
Improving Sample Efficiency in Model-Free Reinforcement Learning from Images by
Denis Yarats, Amy Zhang, Ilya Kostrikov, Brandon Amos, Joelle Pineau, Rob Fergus.
Citation
If you use this repo in your research, please consider citing the paper as follows
@article{yarats2019improving,
title={Improving Sample Efficiency in Model-Free Reinforcement Learning from Images},
author={Denis Yarats and Amy Zhang and Ilya Kostrikov and Brandon Amos and Joelle Pineau and Rob Fergus},
year={2019},
eprint={1910.01741},
archivePrefix={arXiv}
}
Requirements
We assume you have access to a gpu that can run CUDA 9.2. Then, the simplest way to install all required dependencies is to create an anaconda environment by running:
conda env create -f conda_env.yml
After the instalation ends you can activate your environment with:
source activate pytorch_sac_ae
Instructions
To train an SAC+AE agent on the cheetah run task from image-based observations run:
python train.py \
--domain_name cheetah \
--task_name run \
--encoder_type pixel \
--decoder_type pixel \
--action_repeat 4 \
--save_video \
--save_tb \
--work_dir ./log \
--seed 1
This will produce 'log' folder, where all the outputs are going to be stored including train/eval logs, tensorboard blobs, and evaluation episode videos. One can attacha tensorboard to monitor training by running:
tensorboard --logdir log
and opening up tensorboad in your browser.
The console output is also available in a form:
| train | E: 1 | S: 1000 | D: 0.8 s | R: 0.0000 | BR: 0.0000 | ALOSS: 0.0000 | CLOSS: 0.0000 | RLOSS: 0.0000
a training entry decodes as:
train - training episode
E - total number of episodes
S - total number of environment steps
D - duration in seconds to train 1 episode
R - episode reward
BR - average reward of sampled batch
ALOSS - average loss of actor
CLOSS - average loss of critic
RLOSS - average reconstruction loss (only if is trained from pixels and decoder)
while an evaluation entry:
| eval | S: 0 | ER: 21.1676
which just tells the expected reward ER evaluating current policy after S steps. Note that ER is average evaluation performance over num_eval_episodes episodes (usually 10).
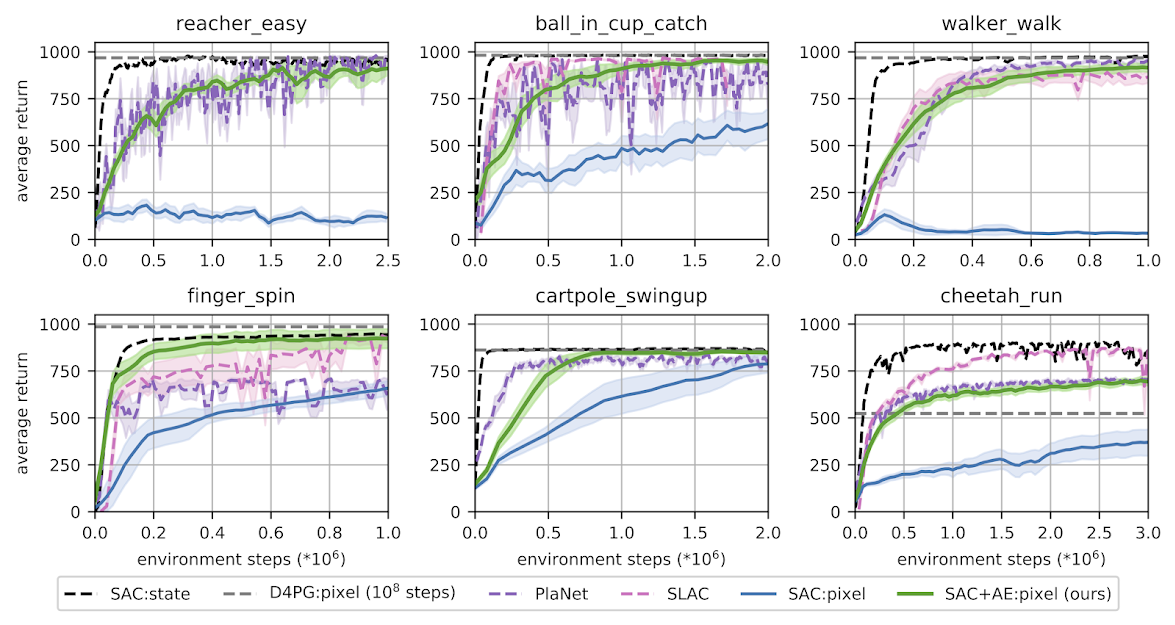
Results
Our method demonstrates significantly improved performance over the baseline SAC:pixel. It matches the state-of-the-art performance of model-based algorithms, such as PlaNet (Hafner et al., 2018) and SLAC (Lee et al., 2019), as well
as a model-free algorithm D4PG (Barth-Maron et al., 2018), that also learns from raw images. Our
algorithm exhibits stable learning across ten random seeds and is extremely easy to implement.